Python格式转换
将OD_Matrix_Weekday_BusyHourAM.csv转换成OD_Matrix_Weekday_BusyHourAM.json。
在数据可视化中,OD弦图要求以百分比的输入格式,也可以用具体的客流数值,但是需要修改一下绘图的js脚本。由于目前数据处理的结果主要是二维表形式的csv,与弦图要求的输入格式不一致,所以这里按照需求先进行额外的数据格式转换,OD_Matrix_Weekday_BusyHourAM.json 是站点之间的OD流量,这个例子json文件中每一行表示该站点到其他各个站点的客流占总客流的百分百,所以都是很小的数值。
下面讲代码实现:
1 | #List.py 数据格式转换的python脚本 |
在同一文件路径下,执行以下命令完成数据转换:
python list.py OD_Matrix_Weekday_BusyHourAM.csv >OD_Matrix_Weekday_BusyHourAM.json
涉及的相关背景知识总结: 1.CSV模块是Python的内置模块,Import csv 就可以调用,CSV模块主要就两个函数:csv.reader()——读取csv文件数据,csv.writer()——写入csv文件数据。csv产生的数据都是字符串类型的,它不会做任何其他类型的转换。 2. use “\t” for delimiter 进行分界 3. 数据结构的推导式(List comprehension),也叫列表的解析式。比如现在我有41个元素要装进列表中,普通的写法是这样的:
1 | a=[] |
下面换成列表解析的方式来写:
1 | a = [i in range(1,42)] |
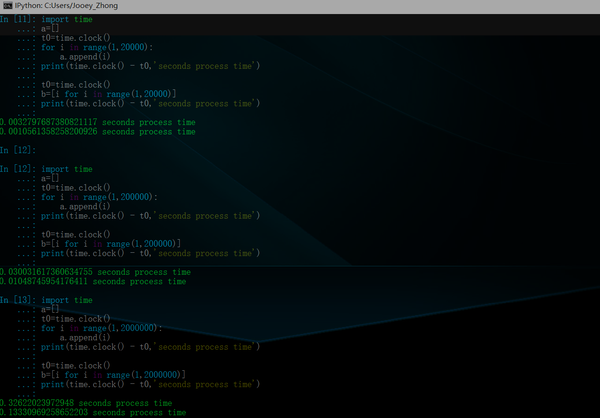
后者执行效率高,我们用time clock()方法,以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更好用。但是这里有一点要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是”进程时间”,它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行时间。(实际上是以WIN32上QueryPerformanceCounter()为基础,它比毫秒表示更为精确) 1.列表推导式的用法:
1 | List=[item for item in iterable] |
2.字典推导式用法:
1 | d={i:i+1 for in range(4)} |
3.用来衡量比较这两种方式程序的耗时:
1 | import time |
得到结果:
3.python: import csv file (delimiter “;” or “,”)
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jyzh@yahoo.com
文章标题:Python格式转换
文章字数:955
本文作者:Jooeys
发布时间:2020-02-26, 20:51:31
最后更新:2020-02-26, 20:51:31
原始链接:http://jooeys.github.io/2020/02/26/Python%E6%A0%BC%E5%BC%8F%E8%BD%AC%E6%8D%A2/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

